I assume you mean decrease in entropy (i.e. increase in information). I did some napkin analysis for the increase in information (in bits) for each OS.
Based on the update ping platform statistics found here: Applications – Tor Metrics we can probably form a decent prior that the distribution of desktop TOR users is roughly 600k Windows : 120k Linux : 100k MacOS. Turning these into fractions of total we have:
Windows: 73.17\%
Linux: 14.63\%
MacOS: 12.19\%
Taking the inverse of these we get the multiplier on the likelihood that an adversary will guess correctly in attributing a given new flow to an existing known flow, knowing that OS will be the same.
Windows: 1.36X, Linux: 6.83X, MacOS: 8.2X.
Total average daily users is currently ~2 mil. If we do a very conservative estimate (on the side of Sam Bent’s position) and assume all users disabled javascript, we’d have a base likelihood of an adversary guessing that a given flow was the same source as another flow, it would be 1/2 \text{ million} or about a 0.00005\% chance.
Multiplied by the relevant multipliers, we get:
Windows: 0.00005\% * 1.36 = 0.0000683\% or 1 in 1.4 mil
Linux: 0.00005\% * 6.83 = 0.000341\% or 1 in 293 k
MacOS: 0.00005\% * 8.2 = 0.00041\% or 1 in 243 k
This is probably an insignificant information gain in practice for any real attacks, and I probably didn’t take into account other assumptions that may change this figure up or down. I’d imagine other attacks such as correlation attacks would give much higher informational returns. However I still think it might be nice to be able to join the majority (Windows) if you have JS disabled. Should TOR not try to minimizing information leakage where it can? Beyond UX / Tor detection / blocking, what’s the argument against this being auto-enabled for hidden services or enable-able via a visible user toggle? (Perhaps even one that specifically labeled the bits of information you were likely exposing in exchange for the gain in convenience ).
Edit: Reread your comment, I suppose this is a question for @TorProject. Given this calculation I think Sam Bent is probably blowing this out of proportion, but I’d never say no to slightly improved practical anonymity, so I’d be curious if there were any deeper reasons why it couldn’t be kept for the most paranoid peeps.
In data science entropy quantifies the amount of information in a set, so a user agent having more entropy means it has more identifying information (i.e. it is less ordered). So increase in entropy is correct. The more uniform a user agent is the less entropy it has.
I mainly point this out because if you choose to do more research into browser fingerprinting on your own you will frequently encounter this “increase in entropy” == “increase in fingerprintability” terminology. That is just how it’s described
Otherwise, your understanding of the math seems to be correct, yes.
I still wouldn’t agree that there is any “improved practical anonymity” to be given back to Tor users though. I think this stems from the same misunderstanding that Mr. Bent has, which is the belief that: previously there was one (OS) bucket, and now there are four.
This is an untrue statement. The reality is that there have always been four buckets of users. One of the labels on those buckets used to match the others and now they don’t, but the buckets themselves were always distinct and distinguishable regardless of the one label.
Once this is understood then I think you realize there has been no practical change in anonymity this entire time, which is also what Tor Project has been saying.
Of course if they could make everyone look like Windows that would indeed be better, nobody is arguing against that. The only point I have ever made is that “everyone looking like Windows” was never the case before, so it isn’t something that Tor has taken away from users. Perhaps someday they will be able to make OS users indistinguishable, and that’d be great.
I agree this is true with JS enabled, but I wasn’t quite sure if it was true with JS disabled. I did some more research and found that CSS can uncover most browser-OS pairs (including TOR browser). We might assume that motivated attackers might invest in this kind of fingerprinting, but I imagine HTTP header versions would be the larger attack vector since I imagine they are often logged (potentially unintentionally) and those logs could be potentially stolen from compromised servers. Given the entropy calculations above, it doesn’t seem to be as big a deal as Sam Bent makes it out to be regardless, but it still makes me wonder if there is any good reason not to keep it as a user-opt-in for when javascript is disabled for the slight extra increase in anonymity in certain contexts (i.e. contexts where you don’t have websites actively doing CSS fingerprinting, but might log header version strings). Does anyone know of any further arguments against enabling header spoofing for this specific scenario?
Also, I imagine it’d be nice to have the code around ready to be made default if the TOR devs ever do manage to iron out all the potential OS fingerprint leaks.
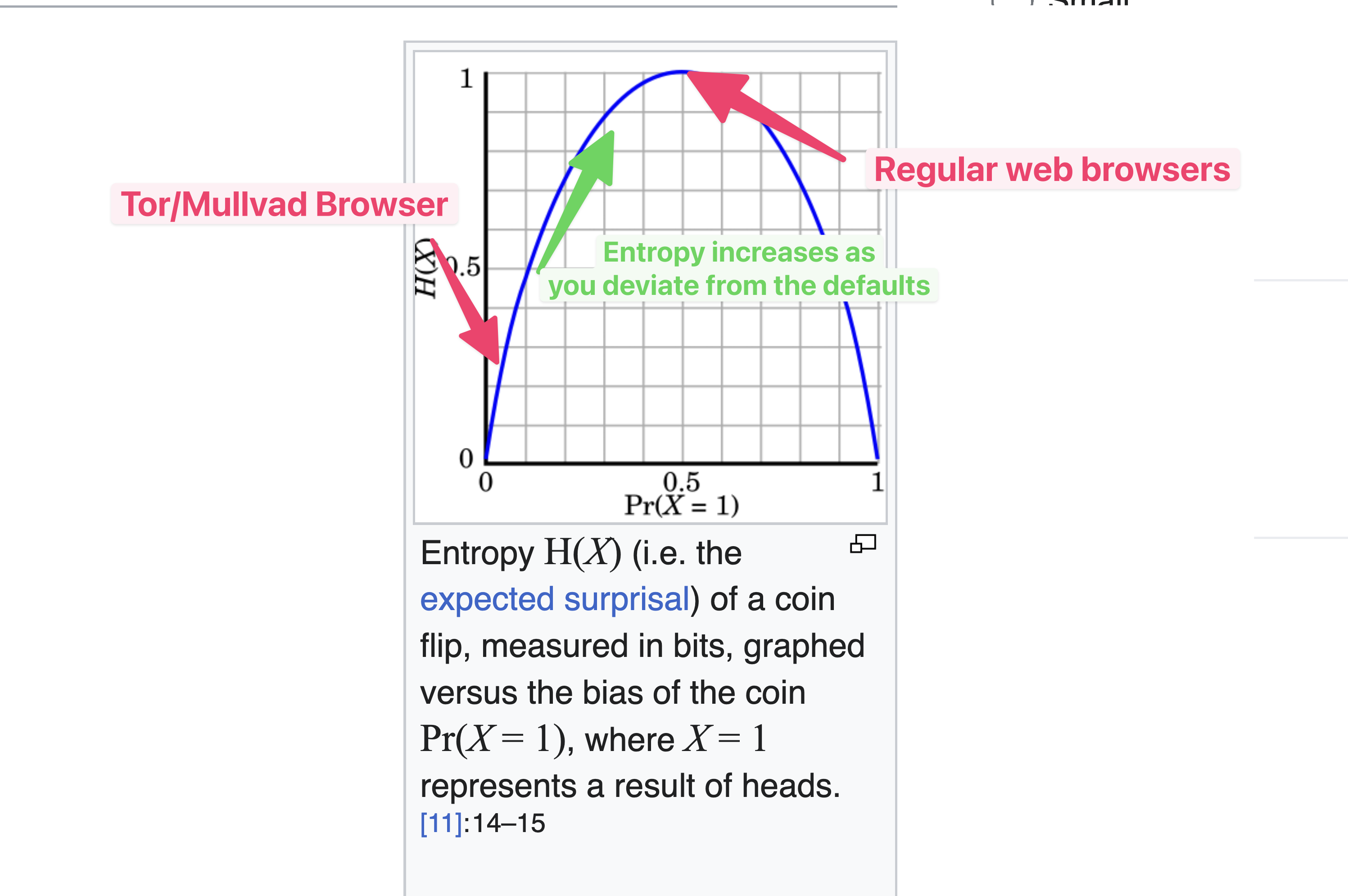
Uniform probability yields maximum uncertainty and therefore maximum entropy.
My understanding is that entropy is the measure of the minimal number of bits of additional information required to narrow down a given probability distribution to a single event/member. A a uniformly distributed anonymity set would have an entropy in log_2 of the size of that set, an anonymity set with 1 user would have an entropy of 0. Thus any additional information that decreases the anon set (i.e. an OS identifier) would decrease the resulting entropy of that anonymity set through bits of identifying information. The resulting entropy would be \text{entropy of original set} - \text{info bits} = \text{entropy of new set}.
Tor Browser has always limited user agents to general categories–Windows, macOS, Linux, or Android in JavaScript, and Windows or Android in HTTP Headers. That means we spoof the OS version and architecture, which was always the approach in JavaScript–now it’s consistent in HTTP headers too (May 2025 Tor News)
I think for most people watching the video and probably for him, this paragraph is just way too advanced for them to understand. The whole thing might just be a misunderstanding but yeah its sad he just decided to jump straight to conclusion and stir up drama
Stay tuned because we’re working on some resources and interviewing some experts given how complicated this topic is, and I’ll update this post when we have more to share.
Oh I see the confusion. Uniform probability is the state that normal browser fingerprints are in, because browser fingerprints are effectively random given the number of factors they are in. Tor Browser doesn’t aim for uniform probability, it aims for a consistent outcome, which means the probability of one specific outcome approaches 100% while the other possibilities approach 0.
In Wikipedia’s example with a coin flip, you can imagine Tor Browser is like a coin that has been artificially made to never result in heads, whereas a normal browser is a fair coin.
As for the entropy discussion, I think we are using the same fundamental definition of entropy, but for different random variables. I am referring to the random variable X=\text{probability that flow #1234 can be attributed to user x}. I believe this is the notion of entropy, specifically the “bits of information” metric used in tools like EFF’s Cover Your Tracks tool. It is fundamentally referring to the ability to narrow down an anonymity set or probability distribution over a set of users with uniquely identifying information.
IIUC, you are referring to the random variable Y = \text{probability of seeing fingerprint y for average web host}, which in an ideal world would be H(Y)=0 (everyone has the same fingerprint).
I think my notion is more instrumentally useful in this context as it inherently takes the total number of users into account and allows users to calculate their own “base” entropy (based on their expected anonymity set size for their chosen model of adversary) and then factor in the impact of various QoE-privacy tradeoffs to figure out the probability they will be matchable to their past behavior.
For example, lets imagine a user visits once a day at a random time an onion site that gets 16 users/day. The user’s anonymity set (and resulting entropy) from the context of the onion hoster in this context would be very small (log_2(16)=4 bits of entropy). For the user to get their true likelihood of being matched to past traffic, they can take this base entropy of 4 bits and subtract the identifying information gain from other sources (i.e. the OS label) and deduce that their true entropy is 2-3 bits, or that they have a 1 in 4 to 1 in 8 chance of being matched to their past traffic. If they expect that a given visit to the site would reduce their entropy to 0, they can rationally decide they don’t want to do that (if their threat model rates the probability of traffic correlation in that context as significant negative utility).
Honestly, that might be cool to integrate into the TOR browser, every link you click has an “expected entropy reduction” for different models of attackers, taking into account past behavior and knowledge about the site in question . Could potentially put more power in the hands of the users for figuring out when their traffic might be correlatable from the perspective of local vs global adversaries.
Yes, but this is also the definition used by Cover Your Tracks in their research, which doesn’t take into account the number of flows to a given web server like you are doing.
It is an interesting concept though. Extrapolating your point to the most extreme case of you being the only visitor to a website, of course it is true that no amount of fingerprint uniformity will protect you from being identified, if you are visitor 1 of 1 to a site (and the website somehow knows that fact)
Nevertheless, I think the main focus of most browser fingerprinting research is on cross-site tracking, not on an individual site tracking you across sessions like I believe you are focusing on, although that certainly is a problem to consider.
Even then you’re still protected right, how are they going to know which Tor browser user it was? Pretty sure as long as you’re using the Tor browser it doesn’t even matter if you’re the only visitor on a certain website.
Hence “and the website somehow knows that fact,” so in theory yes.
I could imagine some scenario where someone creates a honeypot onion service that they get into the hands of a single target. Alternatively (and more likely), the one visitor does some action on the website that identifies them, like inputs their email or sends the website a Bitcoin transaction.
Both of these scenarios are more opsec problems than technical ones, and this is why most fingerprinting discussions center on cross-site tracking in the first place. Hiding information solely from the website you are directly visiting is already relatively easy. It’s much harder when multiple websites collude behind the scenes to track users and build profiles.
A difference of opinion is on the technical side regarding the usefulness and/or feasibility of certain features.
The problem is that they were deceptive in their wording. Sam was accurate in saying they were gaslighting us. That undermines the entire project as it is built on trust.
I guess that this is simply a point we would have to agree to disagree. I think their communication was on point, and that Sam simply did not understand we he was reading, nothing more, nothing less.
We can continue to argue here but this will just fill up this thread without any chance to the outcome.
You can disagree with how they handled this single instance, but the Tor project has been basically be the golden standard with regards to transparency for years. One single instance like this does not mean it “undermines the trust of the entire project”.
Would you mind quoting the actual statement from Tor you found to be deceptive?
My understanding is that Mr. Bent thinks the statement about how Tor works is deceptive because he misunderstands what the situation was prior to this change, which I wrote a bit about in a different thread:
Otherwise, I really haven’t seen a statement from Tor which I could imagine people seeing as deceptive or confusing, but if there is one specifically which you found deceptive then we absolutely should dive into that further.
It will take some time as I will have to go through the video and select what I consider to be the deceptive wording. I appreciate you taking the time to discuss this.
One major issue (perhaps the biggest one for me) that needs addressed is the following line from Tor’s recent statement:“Tor Browser has always limited user agents to general categories-Windows, macOS, Linux, or Android in JavaScript, and Windows or Android in HTTP Headers.”
However, Tor previously said the following, which appears to directly contradict the above statement: "Comparing with the one from Firefox, we can see notable differences. First, no mater on which OS Tor Browser is running, you will always have the following user-agent:
Mozilla/5.0 (Windows NT
6.1; rv:60.0) Gecko/20100101 Firefox/60.0
As Windows is the most widespread OS on the planet, TBB masks the underlying OS by claiming it is running on a Windows machine. Firefox 60 refers to the ESR version on which TBB is based on."
Those two statements appear to be in direct contradiction of each other.
I don’t think those two statements contradict one another. Previously they limited their user agent to windows, now they limit it to either windows, mac, or linux. Saying they always limited it to those is not false, because windows is a subset of the 3 OS categories they listed. This is not entirely unambiguous language, but neither is it necessarily contradictory.
They explicitly said that it has always been multiple categories whereas before they said it was one os: windows. That is a direct contradiction. @Jonah I am interested in your thoughts on this.
Their ambiguous language can be read two ways. You have read it the contradictory way. I provided the non-contradictory alternative, which presumably was what they meant to convey, if they weren’t looking to mislead.